With apologies to Nine Inch Nails.
It has been six months since my last update.
This was not intentional. Prior to this, I was attempting to maintain a cadence of one to two weeks, sometimes slipping to three, between updates.
Unfortunately, in early November, I received this email:
And being the industrious individual that I am, I endeavoured to entirely drain those credits before time ran out. I ran myself ragged in dispatching work to Claude. I stayed up late, woke up early, and found myself acting as I imagine a CPU scheduler would. As a result, my personal projects saw the most productive two months of my life ever.
This was an effort so majestic that it itself took four months to document. It was also rather self-destructive, which is a topic for another day.
Don't try this at home.
the primer
At first, my efforts were slow. The Claude Code Web (hereafter "CCW") interface was buggy and crude - something that has since been somewhat-rectified - but, once I found my cadence, I was enthralled by it and could not let go. Days turned to nights turned to days, all while attending to my day job, all driven by a fiendish desire to drive the credit to zero.
Around halfway through this period (they extended it to collect more training data as a mea culpa for the bugginess of CCW), I found myself in the position of mending some of the more complex PRs with Claude Code locally. In doing this, I was exhausting my regular Claude credits - being a mere Pro peon, of course - so, just for a little bit, I thought I'd upgrade to Max and 5x my limits.
This had a very, very unfortunate side effect: it increased the amount of free credits I had from 250 USD to 1000 USD. This posed a significantly more intractable barrier to overcome, but try and try I did. Every project I could think of that I was willing to submit sloppy PRs to (i.e. owned by me, or close to it), received sloppy PRs.11"sloppy" in the sense that they came straight out of an agent, not that they were, you know, sloppily implemented. I made sure that they did what they were supposed to do, or left the codebase in a state where the work could be continued.
By now, you have seen the length of this post and its table of contents. I want you to know that - despite all of my efforts, and despite the hundreds of PRs I submitted to dozens of projects - I was only able to get down to ~460 USD of credit in the time period.22I'm not sure what the final number was; to my dismay, the credit expired while I was asleep.
At this point, however, I was empowered. I kept going: throughout December, and through my holiday, I created more PRs, reviewed old PRs, and continued to indulge my madness. This post, then, covers the period between and . The end date is somewhat arbitrary, but I had largely eased off the gas pedal by this point.
Let's start with the first, and the biggest, project.
#pyxis
Pyxis is a schema language for memory structures that I have been attending to on-and-off for the last few years. The process of modding games (and other applications) starts with reverse-engineering: using a variety of techniques and tools, one comes to understand behaviours of interest in the application, and how data flows through to enable those behaviours, and how that data is structured.
Once you have that understanding, you need to be able to use it within your mod to affect some change in the game. Modifying code is a relatively-solved problem: you can "detour" functions such that, when they are executed, they will instead execute your code, through which you can intervene and change the game's behaviour. Combine enough of these detours - or patches33Instead of detouring functions and replacing their behaviour/the arguments with which they are called, you can instead patch individual instructions for isolated behavioural changes.
You can go surprisingly far with this: disabling a single condition and making it always-on or always-off can radically alter a game: after all, all God Mode does is disable your ability to take damage. - and you can direct the game as you wish.
However, as part of this, you need to be able to represent and manipulate the game's data structures. Because we're relying on a reverse-engineered representation, we do not have a complete picture of these structures, and even when we do, they are not guaranteed to match the representation of the language our mod is written in. Additionally, not all mods are written in the same language. This makes representing these structures challenging and often language-specific.44As an example of such a solution, FFXIVClientStructs documents Final Fantasy XIV's internal structures for C# and the IDA decompiler. The latter effort is supported through a Python script that ingests a monster YAML file, which works, but, well, look at it...
Pyxis is an effort to solve this: these structures are defined separately from your implementation language, and then compiled to a byte-perfect representation of that structure for your language. It has been in use in a few projects - none truly released, as it were - but, being a side project of a side project, I have never dedicated the time to fill in the potholes and address the features you'd come to expect from a modern language. The issue list grew longer and longer, with no resolution in sight.
Of course, these last two months finally gave me the leverage needed. Let us begin.
The first feature I added was associated functions support for enums (, +128 -1). Pyxis is largely patterned after Rust, so this was just one more step towards ensuring relative parity. In doing this, I noticed that CCW was struggling to test Pyxis the same way I was, so I made sure that the CI used the same testing methodology (, +1 -4). Once that was in, it was off to the races.
I added freestanding functions (, +219 -22) (so that functions can live at the module level instead of only inside impl blocks), and then a min_size attribute (, +298 -7) to allow specifying the minimum size for a type (i.e. what the developer probably intended) while having the compiler round it up to the nearest alignment boundary (i.e. what the original compiler actually produced).
The next chunk of work was by far the most invasive: a complete parser replacement. Pyxis was originally built on top of syn because of how much surface syntax it shared with Rust, but as Pyxis developed, it became increasingly clear that syn wasn't the right fit, especially with my desire for human-friendly diagnostics (patterned after Rust in every way!). My first stab at this was with chumsky (–, +3130 -876, closed), but it wasn't cohering (alas, I don't remember the details as to why).
Because of this, and my desperate need to burn Claude Code credit, I pivoted to a hand-rolled tokenizer with a recursive-descent parser (–, +5056 -749); this let me control the exact behaviour (especially with regard to matching how Rust parses literals), and allowed me to weave in diagnostic information from top to bottom.
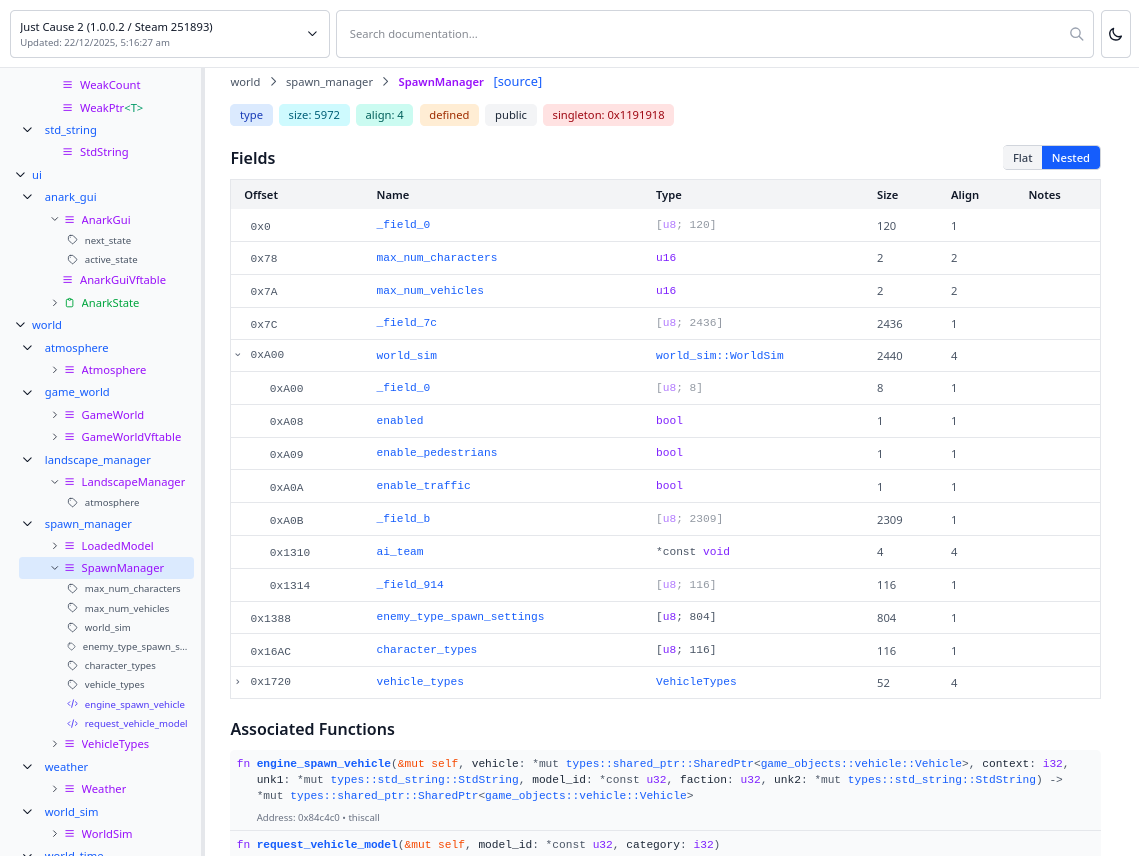
In parallel to that, I started building out the infrastructure for a pipeline for documentation (inspired by, you guessed it, the Rust programming language). I added a JSON backend (, +3916 -11) that emits a single output.json describing the project's items (types, modules, etc). The first consumer of this was a React frontend for viewing docs (, +3366 -1) (pictured above), making it easy to view the resolved types and share them with other people. This was then followed up with the inclusion of the per-backend output statements in the JSON output (, +51 -1) so that they could be surfaced in the viewer. As part of this, I moved all of the definitions from our various projects into a public pyxis-defs repository.
You can't have a Rust-like language without a formatter, so I added a pyxis fmt subcommand (–, +594 -152), then fixed several lurking formatter bugs (, +393 -31). This was made much easier by the parser work; while it would have been possible to do with syn, our custom representation with full span information made targeting our particular formatting constraints relatively straightforward.
Prior to all of this work, the diagnostics produced by Pyxis were perfunctory: panics and bubbled-up errors without context. To address this, I started threading spans through every node in the semantic layer (–, +6550 -4011), so that errors could point at the actual source location of the problem. To round out November, I made the viewer behave better on mobile (–, +290 -88).
Picking back up in early December, I started off by reverting an abstraction I'd introduced earlier (, +1610 -1326): a Located<T> wrapper that was meant to thread span information through the AST. My initial thinking around this was that nodes could be annotated with spans, and code that didn't need that information could choose to forego the wrapper. Unfortunately, as it turns out, the vast majority of a compiler needs to be able to identify where something came from for producing diagnostics - it's simpler to always include spans within the nodes (both grammar and semantic).
I then implemented Rust-style braced imports (, +696 -35) so that use math::{Matrix4, Vector3} would work, and made an initial attempt at type aliases (–, +943 -5, closed) that didn't quite pan out, but was good practice for when I would reattempt it later.
A while after, I spent some time on structural cleanup. I reworked how source files are tracked and shared between compiler phases (, +443 -365), centralising the source files and reducing the number of copies. I hardened the parser against panics on malformed input (, +294 -87) by using bounds-checked access. I bumped ariadne from 0.4 to 0.6 (, +59 -28)55When left unchecked, LLMs will use the version of the library that was available at their training data cutoff. This is something you should watch out for. and converted LexError from a struct to an enum (, +129 -76) with one variant per error kind, matching what SemanticError was already doing.
I returned to type aliases and shipped them properly (, +855 -74), extended the viewer with a nested memory layout view (, +310 -3) and extended the JSON backend with source file paths and line numbers (, +1171 -204) so that the viewer could link to the appropriate definition in pyxis-defs.
A more significant change was to improve the diagnostics for unresolved type references (, +492 -125). Previously, Pyxis's semantic phase attempted to terminate type resolution by finding a steady state in which all references resolved to a concrete type. This was fine as a first-pass solution, but it meant that an unresolvable reference would result in a type resolution will not terminate error that listed all of the types that could be resolved, but not the types that could not be resolved (i.e. the exact opposite of what was required to find the issue). This PR reworked the algorithm, which allowed for a diagnostic that directly pointed the user to the invalid reference.
The next big swing was generic type support (, +5271 -1071). Some of the types we needed to model were generic - notably, C++ smart pointers - and Pyxis did not have a good way to do this, which forced the user to specify manually-monomorphised extern types that would be resolved in the output. In the original issue, I kept the scope small - making just those extern types generic - but I figured I'd take a shot at the full thing, and I'm glad that I did. With generics in, I took the opportunity to remove a fair bit of accumulated duplication (, +176 -331) across the compiler, and to introduce derive macros for the location traits (, +505 -885).
Seeing my success with the generics empowered me to keep going further. I implemented Rust-style privacy semantics (, +524 -8), where private items would only be visible within the same module or its descendants, and made both the type resolver and the use validator respect them. I made the predefined-type mappings in backends explicit (, +43 -11): previously, the Rust backend was relying on the coincidental name overlap between Pyxis primitives and Rust primitives, which would immediately break for other languages. I added a CI job that rebuilds pyxis-defs against the current pyxis (, +43 -0), which would raise a warning if anything outside of the generated docs/index.json changes.
After that, I added atomic integer and boolean primitives (, +697 -210) (AtomicBool, AtomicU8/AtomicI8, and friends), mapped to their :sync::atomic equivalents in the Rust backend, and implemented transitive verification for the copyable and cloneable markers (, +574 -1), once again matching Rust's semantics.
To finish, I tended to the test infrastructure. I refactored the test assertions to use exact structural matching against error variants (, +515 -547), and split the 3200-line semantic test file into per-feature modules (, +3373 -3223) (basic_resolution.rs, imports.rs, enums.rs, generics.rs, and so on). These were long-overdue refactors that I was putting off, as a result of the activation energy required to get them going, but it's hard not to do them when they're one prompt away.
#perchance-interpreter
Perchance is
a platform for creating and sharing random generators
but if you search for it now, the top results are the free AI image and text generators it offers, which I find to be a shame, because Perchance-proper is a fascinating project in itself.
In exploring its generators, you will find a vibrant community - and ecosystem - defining procedural generators that span all kinds of interests and fandoms. Generators can be used from other generators, enabling a beautifully intertwined network of emergent complexity. Any fan of procedural (not generated!) text should play around with it: alongside Tracery, you will find some of the best examples of the medium.
Unfortunately, the relationship between the Perchance interpreter and language is much like the relationship between MediaWiki and Wikitext: it was implemented as an ad-hoc wrapper around its implementation language (in this case, JavaScript), and is impossible to decouple from its operating environment. For a variety of reasons, I have been interested in running standalone Perchance generators outside of the Perchance website - but, as a result of this, that's just not possible.66Perchance's solutions for this involve making requests to an API or downloading an all-inclusive HTML file for the generator. Regrettably, neither of these options allows for a generator to be embedded in an offline, non-web application. I mean, I suppose you could use something like Lightpanda to run the latter, but that is a pit of misery from which you will not escape.
I've wanted to address this for a long, long time. I - and others - have attempted to do this in the past, but the scope of the task is just too large without weeks and months of dedicated effort, which I was unwilling to provide.
I assume you can see where this is going. I extracted the base documentation for Perchance as a Markdown document, raised my Claude Code hammer, and then I proceeded to build a Rust interpreter for Perchance (–, +5102 -2). I did this by saving the core documentation for Perchance (represented as HTML or as the output of a generator itself), including several test cases, then passing it to Claude to produce a Markdown document, which I then gave to Claude Code. In hindsight, I wish I'd saved this resulting spec to allow Claude to reference it later.
This was not done without some thought, of course. I wanted the interpreter to abide by several restrictions: notably, I wanted it to be as dependency-free as possible, to make it easier to embed in other things, so I elected to build my own parser. This would have normally been a very tedious endeavour, but the interesting thing about vibe-coding is that both the easy and the hard routes work out to the same amount of time investment - so there's no excuse not to take the hard-for-you, good-for-your-users route. Interestingly enough, this was around the same time that I made the same decision for Pyxis: I suspect that one gave me validation that the other would work, but I couldn't tell you which one now.
With an interpreter now in hand, one thing became clear: that was the start of the journey, not the end. Upon testing it, I immediately noticed that a variety of generators failed, so I gave it tests and told it to make them pass (, +480 -8), then had it fix indentation issues with the parser (, +80 -15). As it turns out, I'd given it an incomplete version of the documentation, so rectifying that gave me more tests and more compliance (, +219 -22), and then I did that two more (, +310 -54) times (, +2 -0).
With the interpreter now mostly functional, I needed a way to test it out, so I built a React frontend (with live preview!) (, +5432 -0), then deployed it to GitHub Pages (, +134 -60) - specifically, this very website - and fixed a minor Vite configuration issue (, +1 -0) in the process.77Fixing the configuration issue would have been faster to do by hand, but I was trying to maximise both my parallelism and my use of credits. This is something friends of mine have mentioned to me: when you have a quota (including today's subscriptions), you feel obligated to make the most of it, even when there are more efficient ways to do the task at hand.
At this point, the interpreter was able to execute any single, isolated, generator well. One of Perchance's most notable features, however, is being able to invoke other generators: this lets you reuse existing generators - including those of other people - and compose them into your own generator, in turn growing the output space for your own generator.
It was thus important that I implement the ability to import and export generators (–, +14599 -616). There was some nuance in this, as I had to think about how to implement this within the pure design I had for the interpreter: for the same set of inputs, the interpreter should produce the same output. In the end, I chose to have the interpreter take an async trait that mediated the sourcing of imported generators.
After this, I added a built-in for joinLists (, +460 -14). This is a little controversial: this is not a built-in in Perchance; it is instead an imported JavaScript plugin. The truth about Perchance is that it is actually all JavaScript - the language can be considered, in some ways, an alternative frontend for JavaScript - but I did not want my interpreter to embed a JavaScript interpreter, so I elected to cheat and hardcode relevant plugins instead. A perhaps-more-compatible approach would have been to build Perchance-as-a-JS-library, but where's the fun (and safety) in that?
The existence of joinLists and generator imports allowed me to test out more complex generators, and in doing so, I immediately found myself observing several new issues. Luckily, though, if you can verify it, Claude can fix it, so first I addressed an issue with consumableList (, +211 -23), then updated the README to better reflect the state of the project (, +127 -261), then implemented the features that were noted to be missing in the README (, +731 -60). It is a strange way to develop - having your agent document where the gaps are, and then filling those gaps in with the very same agent - but it is effective!
With this, I was approaching a suitable level of completion for the project: it was easy to integrate, and able to run the generators I cared about. However, in the Post-Rust Era™️, there's no excuse for having poor diagnostics, so I integrated the ariadne library for error reporting (–, +1701 -578), and augmented all code-sourced items with a Spanned type that tracked their origin (, +569 -517). I will admit that this ran counter to the zero-now-low-dependency methodology I was developing with, but in my defence, have you seen ariadne's error reports? Worth it!88This would have also been around the same time I added ariadne to Pyxis. Claude let me work on two compiler-shaped projects at the same time, and the lines began to blur in my decision making as a result.
I took stock and had Claude look over the current state of the interpreter to update the README and implement any missing functionality (, +639 -25). I would have preferred for these to not go out of sync in the first place. In hindsight, I believe that embedding an instruction to ensure the README remained in sync with the state of the project in the CLAUDE.md would have helped: alas, it took me some time to appreciate the benefits of writing a good CLAUDE.md.
With these changes, I now had a fully-functional Perchance interpreter, at least for the use cases I had in mind. At this point, though, I started to wonder - what can I do with this entirely new implementation, not beholden to the same constraints as the original implementation? And then the answer popped into my head, and it was obvious: add a tracing debugger for generators (, +1512 -85).
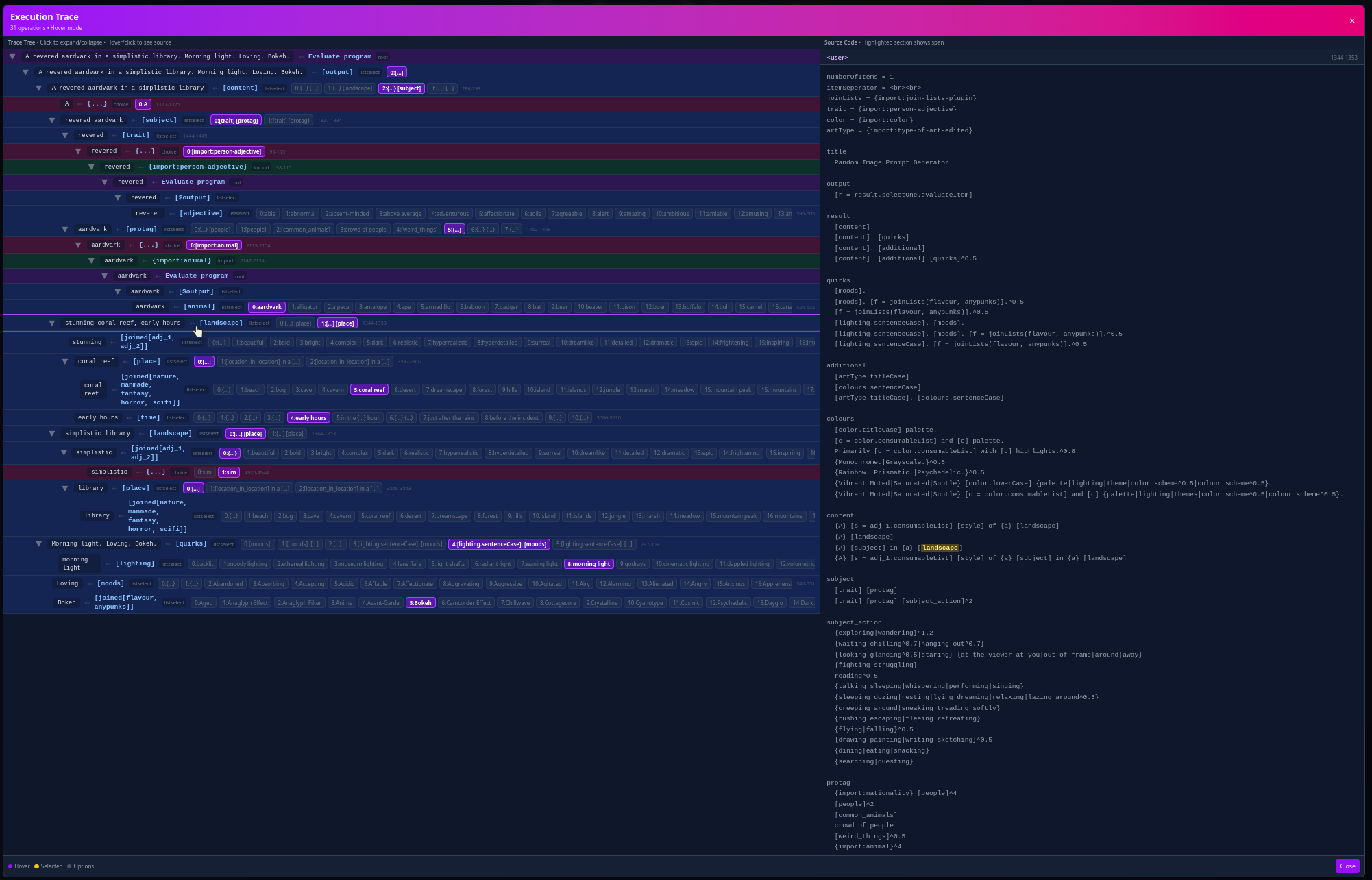
That was particularly inspired, I think. Of course, I'm not wholly happy with how it worked; I ended up later removing the tree view that I had in the original PR (, +17 -374), and there are still a few bugs in the trace view (including items being shown that do not contribute to the final output), but I think these are resolvable issues. I think it is tremendously cool that this is now possible, and debugging your generator is now much less tedious than with the traditional guess-and-check method.
Finally, I refactored the evaluator into multiple modules (, +3394 -3089). A rather dull note to close out on, but one important to note, I think: left to their own devices, the agents will produce repetitive slop, but you can also use them to unslop by having them refactor the code to a better state, especially if you're actually looking at the code and can see where they're deficient.
As a whole, I'm quite happy with how this turned out. As mentioned at the start, I have always wanted an alternate embeddable implementation for Perchance, and now one exists. I do not think it is perfect: I am sure that there are behavioural differences from the original, and there exist bugs that permeate the codebase that I am not aware of, but these are fixable issues in a way that "an embeddable Perchance interpreter does not exist" was not.
#paxcord
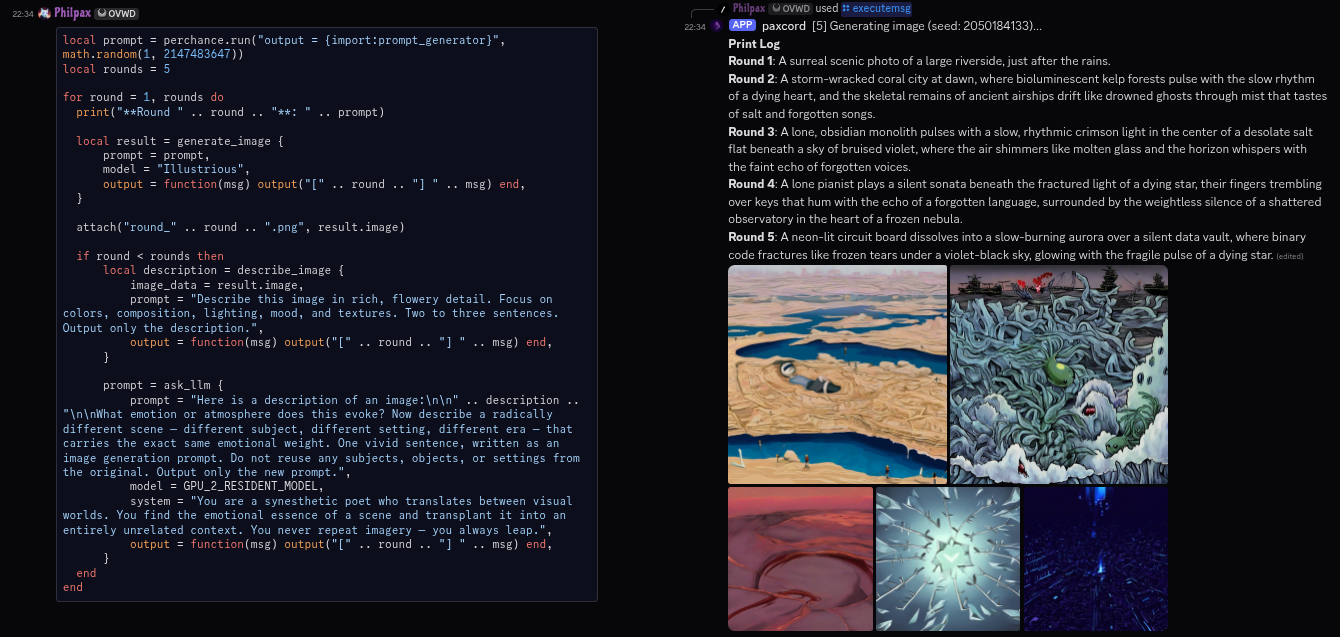
paxcord is my personal Discord bot, optimised for my own use cases. Notably, I am a fan of the Lua programming language, and I've carried that into this here bot by orienting it around Lua. The work here was primarily in extending that capability to the point of near-absurdity.
The first step was to integrate the above Perchance interpreter (, +58 -0), such that I could test out the generator in a social capacity. Once I had my fun with that, I started to think about a new way to interact with Lua, and decided I'd best prepare for it by exposing currency conversion to Lua (, +702 -19).
The new way was simple in concept, but troublesome in execution - it was to convert our existing Rust commands to Lua ( – , +1208 -844), making them much easier to iterate on and to add new commands with. CCW's methodology proved to be a bad fit for this - it was very much not a one-and-done task - as can be seen from the time taken: I had to iterate on the interface and test it extensively.
After that, well, I could finally do what I was working towards. Apologies for the spoilers, but my end goal for the Lua conversion was always to integrate rucomfyui (, +554 -29), so that I could combine Perchance (for prompt generation) and an AI image model for social procedural-generative art. And it worked!
Finally, to close out, I added a Lua reply handler (–, +815 -72) to enable continuing a conversation, and fixed a bug where the first message was not present in the reply handler (, +5 -0).
#jc2mp.github.io
A decade ago, I was a developer on the multiplayer mod for Just Cause 2. I had slowly phased out my involvement over the years - what with university and employment obligations - and primarily remained as an occasional community presence, helping people out where I could and whatnot (ask me sometime about the follies of achievements tied to the presence of team members).
In 2021, an OVH datacentre burnt down. Unfortunately, that also happened to be the datacentre in which the JC2-MP website and all of the surrounding infrastructure were hosted; we had backups, but they were out of date, and the other members of the team were as similarly checked-out as me, which meant that our website remained down for the next few years.
Some time after that, we brought a static-and-simplified version of the website online through GitHub Pages, and that has served its informational role well. However, it was lacking a fairly significant piece: the wiki, which documented how to use our scripting API, among other details. Community members passed their copies of the docs around, and I hosted our (very out of date) backup of the raw Wikitext up on GitHub, but it was clear that it wasn't really a sustainable solution.
The only way to get the wiki in a human-digestible form would have been to stand up a MediaWiki instance, which none of us were willing to do, and so the problem lingered for some time. During 2025, though, I had a realisation: I had built a relatively robust library for parsing Wikitext (for genresin.space), as well as infrastructure for generating static websites in Rust (paxhtml, originally built for this very website). One thought led to another, and I found myself building an SSG to resurrect our MediaWiki dump.
I chose to do this because I wanted something that could be indefinitely hosted without any payment, which suggested the use of something that could be hosted on GitHub Pages. I had started work on this SSG months ago, and it was effectively "done": it could render the entire wiki and all of its pages with wiki-like structure and styling.
Done does not mean deployable, though: our pages were heavily reliant on templates containing partial table syntax, which needed to be evaluated in the correct recursive order to render correctly, and the current implementation most certainly did not. I'd bashed my head against it a few times, but resolving it would have required a level of debugging and experimentation that I was unwilling to commit to, and so it languished.99Wikitext is unbelievably, incredibly cursed. However cursed you think it is, it's more cursed than that. Correctly parsing this requires you to find a steady-state by repeatedly parsing the text, expanding templates through textual substitution, converting it back to a string, and reparsing until there are no more changes. It's awful.
Anyway, Claude one-shotted it (, +417 -87). After that, it was off to the races: improving the Bootstrap styling and adding syntax highlighting support (, +532 -18), then giving up on Bootstrap entirely and migrating to Tailwind CSS (, +86 -82). I then navigated around the generated wiki, noticed that it was a bit difficult to browse without index pages, and sorted that out (, +184 -3).
Once that was done, I formally opened and merged the PR for JC2-MP's GitHub Pages repo (, +26982 -2). It was finally done, and the rest was merely refinement: updating wikitext_simplified to improve error handling (, +49 -27), and adding clientside search through a precomputed search index (, +568 -21).
That last one would have taken me a few days at normal speed, I think: generating the initial index, getting the JavaScript progressive enhancement to work properly, optimising the index, and augmenting the index with the information required for smart-ish retrieval. When iteration is extremely quick, though, it doesn't hurt to try different approaches out and to explore the possibility space.
#blackbird
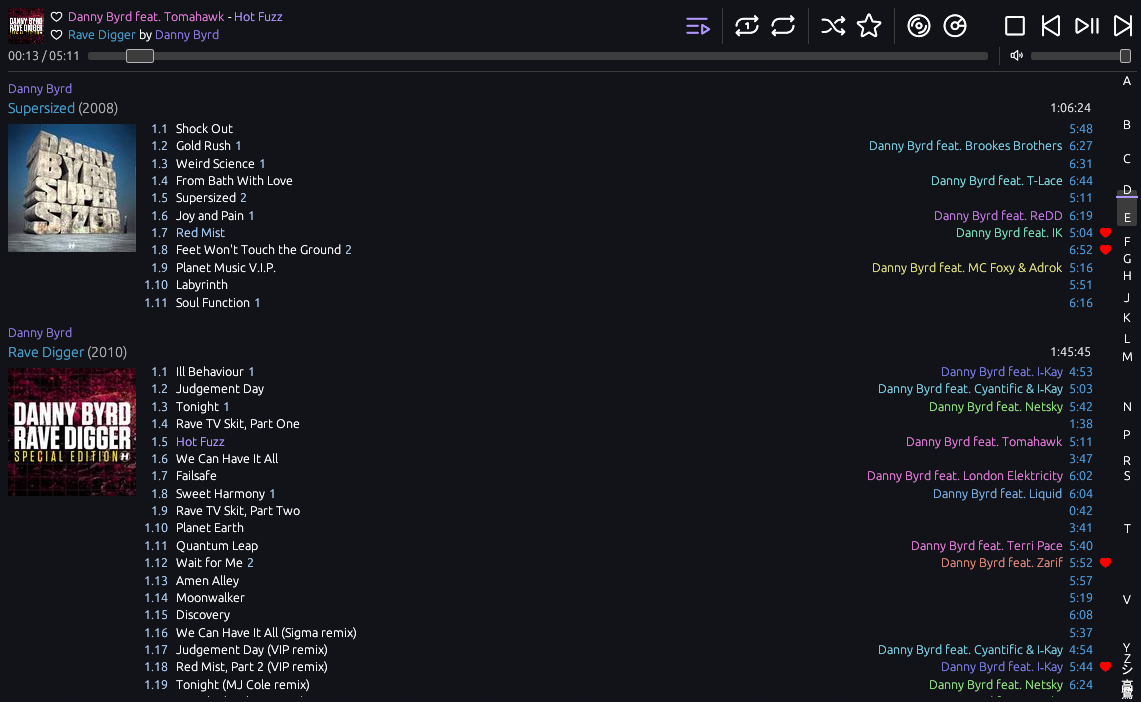
blackbird is my personal music player, optimised for my own tastes in what a music player should do and how it should operate. I grew up using foobar2000 in a very specific way - library view only - and as I started using other operating systems more regularly, I wanted a way to both carry that experience with me and to be able to stream my music from my own server, regardless of where I was.
The latter was easy enough to solve with Navidrome, which implements the (Open)Subsonic protocol, but the former showed itself to be much more difficult: the majority of existing Subsonic clients optimised for iTunes / Spotify-like music libraries, which are heavily playlist-oriented and do not present your entire library in a single linear list. After much hemming and hawing, and after being goaded into it by a friend building their own client, I embarked upon the process of developing my own.1010I'm pretty sure that I "completed" my client and they did not complete theirs, so who's the real winner now?
I'd say that this has generally gone quite well, but the thing about building software for yourself is that you will grow to be bothered by its deficiencies and will seek to address them. I was doing this where I could, but these things take time and effort. My issues list had grown quite large by this point, with two-dozen issues covering common music player functionality like gapless playback, track scrobbling, lyrics, and more. Good chance to burn some credits, then.
The first point of order was to add a tray menu icon (, +162 -25) so that I could interact with my music player from the tray, much as I have with foobar2000 in the past. Unfortunately, this was stymied by two things: Windows's support for tray icons has steadily regressed over the years, and the implementation of the tray icon logic in the library - or perhaps in Windows, it's not entirely clear to me - causes the window's event loop to lock up entirely on Windows until I interact with it again. Still, it works great on Linux! Given that, I added the ability to like tracks from the menu (, +32 -4).
Next on the agenda was addressing playback - both in operation and in functionality - and so I added the ability to like tracks from the now-playing section of the UI (–, +75 -4), the scrobbling of tracks (, +181 -3), liked track/album shuffle playback modes (–, +265 -59), and finally, gapless playback (–, +173 -5). I'd been putting that last one off for a while, because it requires queueing up both the current and next track for the playback thread, which is a quagmire of logic. Delegating it to the agent got me unstuck.1111Not without trouble, though. Until around mid-March, there was a bug in the playback logic where it would occasionally keep the next track queued up for playback after switching playback modes (which reset the logical queue, which in turn should have reset the gapless playback queue). This one, I'm afraid, took Opus 4.6 to resolve. Still, not irritating enough to spend human time on resolving.
Interleaved amongst the previous changes, I had to make the tray icon support an optional feature (, +38 -16) and make rodio and souvlaki dependencies optional (, +32 -4). This was due to the environmental challenges posed by the CCW environment: it often struggled to make any forward progress because the system libraries required to build these were not available. I believe that there may be a way to fix this, but I've not used CCW enough since to investigate further.
On startup, blackbird fetches the entire library's metadata from the server, and streams in the album art as you're viewing it, keeping the previously- and currently-viewed arts in a cache. To avoid pop-in, I added a low-res 16x16 disk-based cache (–, +128 -14) that can be displayed immediately while the real art loads. In addition to this, I also began preloading album art around the next track (–, +118 -34) to assist in mitigating the pop-in when moving to the next track.
I then proceeded to blast through my feature backlog: I added a lyrics view (, +388 -34), supported searching through typing (, +187 -4), added an Apple-style letter display in the scrollbar (, +129 -0), fixed that display (, +101 -48), and added a separate search window, openable through a global keybind (, +223 -155).
After this, some cleanup and consolidation was required, so I moved all of the keybindings to the configuration file (, +228 -25), refactored the UI code to be more modular (, +1336 -1234), and "fixed" an issue where the pseudorandom shuffle algorithm would take me to the same tracks (, +30 -3)1212Another case where I'm not sure it's actually been fixed properly, but it doesn't bother me enough to look further into it. I should do a statistical analysis of where the shuffle algorithm leads me over time, though. Claude! Claude! We have work to do!
Closing out the feature work, I elected to display the playcount for each track within the library itself (–, +54 -14), to add an indicator for the current track within the scroll bar (, +77 -7), and attempted to make the application name show up in the media controls (, +182 -0, closed). As always, Windows made this annoyingly challenging, and I ended up giving up on it.
To close out, I applied a few fixes to the nix-shell (, +8 -0) and made the tray icon initialize properly under GTK (, +21 -3).
As a whole, I would argue that the use of Claude Code (Web) was worth it for blackbird alone: within a span of a few days, I was able to burn through my entire feature backlog and make it the music player that I wanted - nay, needed - it to be. I'm quite happy with the outcome here.
#paxboard
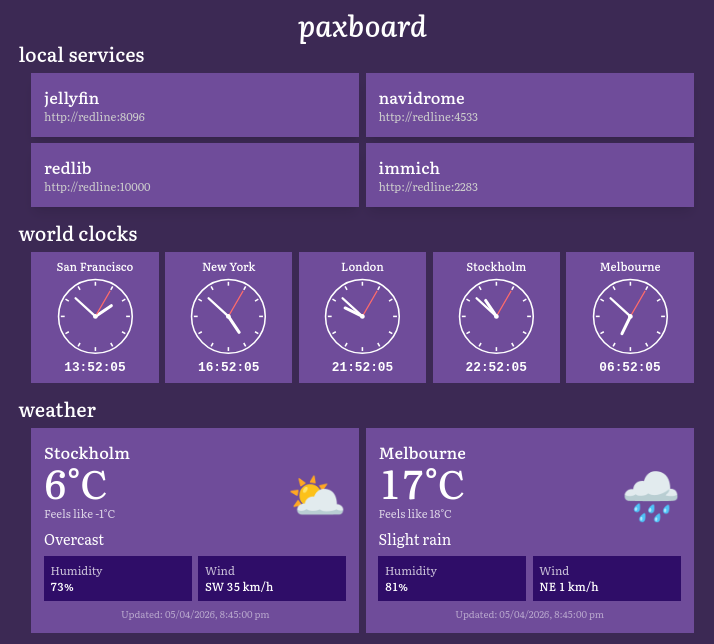
paxboard is my personal self-hosted home page. I am pathologically afraid of YAML, so existing solutions like homepage didn't sit right with me; additionally, I wanted to be able to easily display custom information, like the status of my AI models. My initial version of this was written in Rust and was entirely server-rendered using paxhtml, as I was in a particularly paxhtml-y mood.
However, I'd grown to reconsider this, especially because I wanted cleanly-delivered live updates. As a result, one of the first things I did was to rewrite the codebase in TypeScript and React (, +4521 -2515), making it much easier to iterate (especially with regard to letting me work on the running version). I then proceeded to add world clocks for the cities most relevant to me (–, +160 -0) and made it possible to copy the times of those world clocks to the clipboard (, +81 -1).
I then rounded things out by adding weather displays for Stockholm and Melbourne (, +295 -2) and a system stats view for monitoring the state of my server (, +1724 -20).
This is a relatively small bit of bespoke software, but it's something that I would have otherwise given up on if it weren't for the ease of maintenance. Of course, one could argue that the correct thing to do would have been to use the existing software - but like with blackbird, I wanted something for me.
#rucomfyui
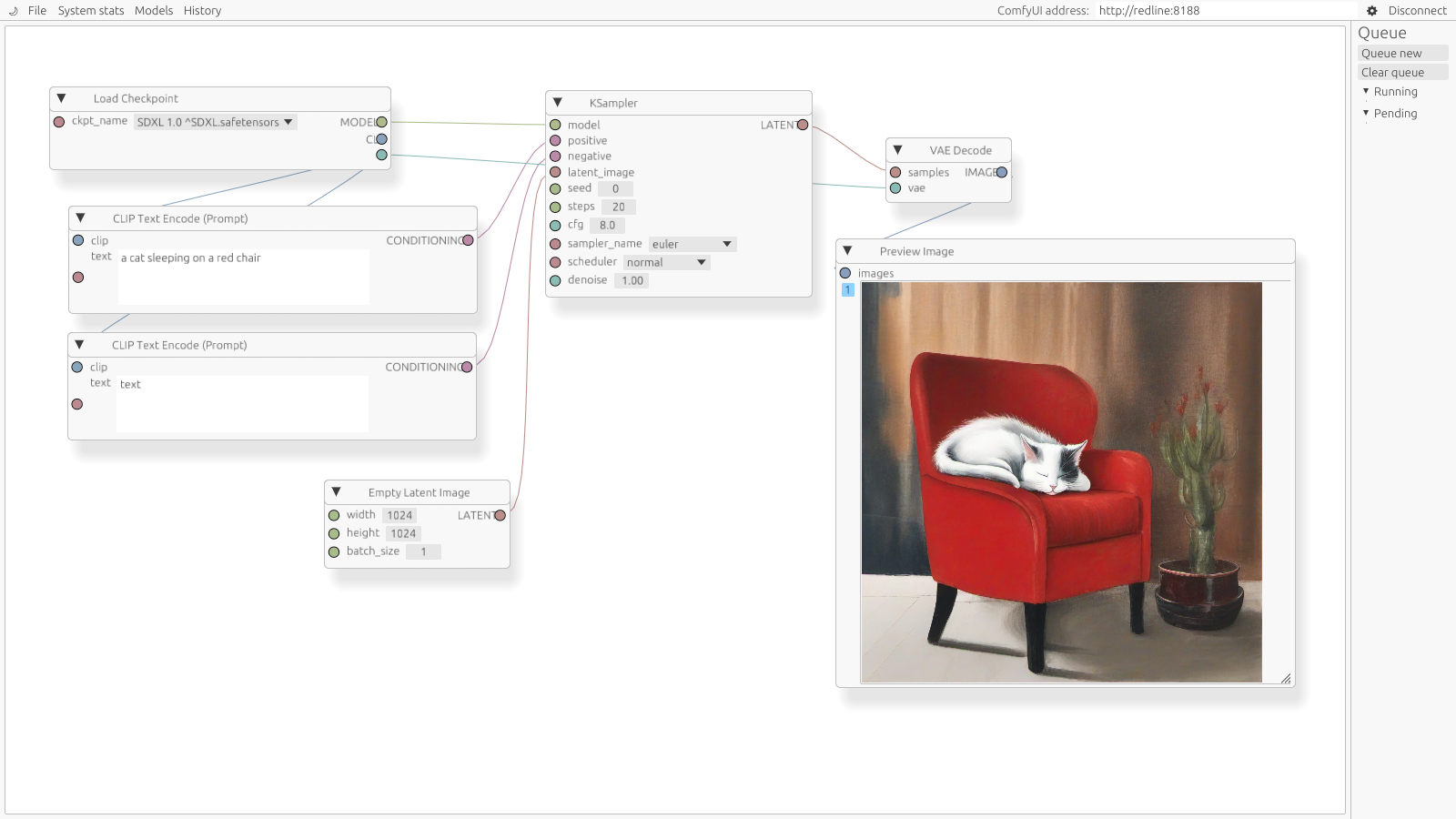
ComfyUI is an open-source node-based program for composing AI synthesis workflows (image generation, video generation, etc). The user composes a graph of nodes that describes the flow of data through the various steps in a synthesis pipeline, and then runs this graph to produce an output.
To help external users make use of the wide ecosystem, it offers an API that can be used to run these workflows. Unfortunately, this API is poorly-designed and even more poorly documented, so using it correctly is both troublesome and tedious. In late 2024, I developed a Rust library for interfacing with this API with a very strongly typed approach in mind, as befitting the Rust ethos: the goal was to make it difficult to "hold it wrong", while simultaneously guiding users through the happy path.
To achieve this, it uses code generation to create strong representations of the dataflow types (the types of the data being transmitted between nodes), as well as of the nodes themselves. This means that a full ComfyUI workflow can be composed from Rust types and be statically checked by the compiler for correctness before being run; in addition, these representations also appear in autocomplete, making it much easier to discover nodes.
I have yet to release it to crates.io, as I wanted to complete some polish work on it first. I made a few steps towards that in this period. (For the record, at the time of writing, I still haven't. I'm pretty sure it's more-or-less ready, though.)
The code generator was fairly heavily-coupled to the internals of the library, so my first point of order was to split the generator out into its own library that could be used externally (, +918 -639). In hindsight, I'm not convinced that this fully solved the problem that I wanted it to solve; it's still somewhat unclear how to wire custom nodes in while still using the existing exposed types. With that being said, though, it does get much closer than it was before.
One of the demo application/libraries for the library wires its semi-typed representation to an egui-based node graph - in this case, egui_node_graph2 - to demonstrate that it is possible to replicate ComfyUI's user-facing interface. Unfortunately, egui_node_graph2 is no longer actively maintained, which meant that I'd never see resolutions to some of the bugs that ailed my use case, and I'd be limited to the versions of egui that it would support.
I considered working around this by bringing the library up to date, but instead opted to port the node graph to the actively-maintained egui-snarl ( – , +586 -363). The initial port was straightforward, but getting all of the functionality to work required extra polish, which led to it dragging on for an entire month.
In the meantime, owing to what paxcord needed, I added a Lua interface for ComfyUI nodes (, +1103 -1), which proved to be surprisingly easy. Most of the work was in planning out what that interface should look like, and I'm pretty happy with how it turned out - it's a very fluent API.
During the process of getting Lua support in, I noticed that the Rust code's formatting was not being enforced at all, so I addressed that with a PR to add the usual kinds of CI (, +192 -70).
Finally, I built a tool to take an arbitrary API workflow graph and convert it to its equivalent Rust and Lua rucomfyui representations (–, +2712 -0). This is something that most other ComfyUI consumer libraries have, and it is very handy: you can interactively build up your workflow in the regular ComfyUI UI (or, say, our very own node graph), and then convert that to a programmatic description that can be parametrised as required.
#ida-c-splitter
While working on my VR mod for Just Cause 3, I found myself wanting to explore the entirety of IDA's decompilation output for the debug build of the game. This representation makes it much easier to search for references to fields and members of classes; IDA's decompiler is very function-oriented, which makes it difficult to cross-reference ("x-ref") class state across functions.
Unfortunately, IDA's feature for collecting all of the decompilation output produces a single C file for an executable, and that file for JC3 is 500MB. The vast majority of text editors will break down at that size, and it's hardly an ideal experience in the ones that do survive. After staring at the output for a while in Sublime Text, I noticed something: it was well-structured enough to enable the construction of a tool to split the output into a hierarchical folder structure, organised by classes and such, which would make it significantly more legible to traditional tooling.
I scoped out the task, and then started by parsing function signatures (–, +3910 -5), using test cases extracted from the binary itself. Actual file tree generation (, +132 -3) was pretty straightforward after that, but both the code and the output were still quite messy.
To help with the code, I tasked Claude with making it a bit more production-ready (, +525 -105) (consisting of reshaping it into something a bit closer to a typical Rust CLI application, adding parallelisation, and generally documenting things).
I then started looking a bit closer at the output, and noticed that it was misbehaving around function pointers, calling conventions, and templated parameters (you know, the usual nightmares associated with parsing the C++ grammar). These were relatively quick to fix here (, +23 -5) and there (, +169 -20) once I'd identified what the correct behaviour should be.
The next problem was with typedefs, which required a slightly more complete type parser. Again, pretty straightforward, with the bulk of the PR being tests (, +12292 -438). Finally, to close things out, I cleaned things up with another refactoring PR (–, +414 -742) and setting up CI (, +89 -0).
I'd like to say that this helped me continue my work on JC3, but as you can see, I was preoccupied by other matters.1313Also, Square Enix released a patch to de-Denuvo the game, which I would appreciate in any other context, but it would have required me to rework all of my existing reverse engineering work to target the clean binary instead, which I haven't been able to motivate myself to do. I would quite like to return to this some day.
With that being said, though, I suspect that the split-decompilation would be quite amenable to analysis by a coding agent, and I'm excited to give that a try sometime - perhaps it can answer questions about the decompiled code the same way it can with regular codebases?
#paxhtml
rust
pub struct HeadingAnchorProps {
pub target : String ,
}
impl DefaultIn < ' _ > for HeadingAnchorProps {
fn default_in ( _bump : & Bump ) -> Self {
Self {
target : String :: new (),
}
}
}
/// An anchor link used before headings and in TOC entries.
# [ allow ( non_snake_case )]
pub fn HeadingAnchor < ' bump >(
bump : &' bump Bump ,
props : HeadingAnchorProps ,
) -> paxhtml:: Element < ' bump > {
paxhtml:: html! { in bump;
<Link target={ props. target } underline additionalClasses={ "mr-1" . to_string ()} >"#" </Link >
}
} paxhtml is a Rust library for generating HTML primarily used by my website. The existing solutions that I found for this were incomplete, not pragmatic enough, or not really appropriate for use in an SSG. It offers both a builder API and a proc macro for building trees of elements, which are then processed into "render elements" that represent the actual HTML to be generated.
I have updated the library as required to accommodate the needs of its consumers (i.e. my other projects using it). One of the bigger changes was to add support for interpolating custom components in the macro (, +334 -32), so that I could easily embed bespoke components in larger views. This was previously done by interpolating a function call without named arguments or optionals, which was rather poor UX; instead, the macro now expands a custom tag into a function call with a struct for args, similar to what other Rust JSX-likes do.
Of course, having empowered my JSX-like with custom components, I now needed a way to use those custom components within the Markdown used within this website. That, too, was a simple matter of making the HTML parser available at runtime (, +860 -314). Not too difficult conceptually, but tedious to do by hand, and trivial to vibe out.
Later on, I was doing some performance optimisations on my website - which builds everything per execution, to ensure hermetic builds - and realised that paxhtml produces many small allocations that would no longer be necessary after the page they belong to was written out. In a domain where the memory allocations are numerous and very clearly bounded, there is but one obvious thing to do: use a bump allocator for everything (–, +1171 -532). I wouldn't have bothered if I were doing this by hand, but Claude made quick work of it.
Finally, as part of the above bump allocator work, I discovered that I had to keep a non-bump-allocated representation around for the Lua bindings I'd produced for paxhtml in a previous edition, for paxboard. As I'd already stopped using these bindings in paxboard in November, I weighed up my options, and came to a conclusion: it was time for the Lua bindings, and their vestigial owned representation, to go (, +1 -744). Claude had surfaced this earlier in the planning phase, but I hadn't realised how much I'd hate having two representations until it was laid bare to me.
#philpax.github.io
This very here website. A long, long time ago, I hosted a Ruby/Sinatra server for my website that was completely unreproducible, but was fully hackable; a less-long time ago, I switched this over to a Zola-generated static site, which was fully reproducible, but completely unhackable.
In an effort to thread the needle and set up a reproducible and hackable solution, I developed my own Rust SSG. As with many of these things, I didn't do it because it was easy; I did it because I thought it would be easy. It took me the better part of a year to put together a design and structure I was happy with, which was largely an unforced error: as it turns out, people pre-design their websites in Figma for a reason.1414Ironically, the needle has swung back in the opposite direction these days: it is so easy to iterate on design with an agent that at least a few people are opting to skip the Figma phase entirely. I certainly did for my most-recent work project.
With that being said, though, it's done, and it works, so the only thing that remained was to make it better, which I did.
I introduced custom component support for the compile-time JSX-like syntax in paxhtml, so it was only natural to port my existing custom components over to it (–, +122 -78). This is something I should have done much sooner: it made interacting with these custom components much nicer, especially for things like links, which are rather commonplace.
After I saw one of Jake Lazaroff's social media preview images (i.e. OpenGraph images, shown when the page is posted to social media), I was suitably inspired and elected to build my own preview generator (–, +755 -48), the result of which you can see below. As you might expect, CCW did not execute on the design I'd described in an aesthetically-pleasing way, but it did set up the necessary rendering scaffolding. I iterated on it locally until I had something that I was happy with.

I've never been truly satisfied with the light mode on my website; it is as perfunctory as it seems. I let Claude have a go at it (, +4 -4), including adding support for light mode to code blocks (, +148 -8), and it's better now, but I'm still not truly happy with it. I fear a general redesign is in my future, but I will stave that off for as long as I can.
Speaking of code blocks, around this time, fasterthanlime published arborium, a crate offering all-in-one syntax highlighting. To this point, I had been using syntect, which has served me well, but required additional infrastructure on my part to support the theme and syntax sets used by my website. I saw an opportunity, and decided I'd try it out by having Claude replace syntect with arborium ( – , +383 -1659). As you may be able to tell from the diff, this reduced a fair bit of bloat; the only downside is that it slowed down my builds, which gave me a good excuse to do performance optimisations elsewhere.
So that's what I did: I switched paxhtml over to use bump allocators, and then I integrated that work into the website proper (, +479 -302). The time savings were quite significant - we generate quite a lot of garbage in the process of rendering a single page, it turns out - and with that success, I figured I'd let Claude squeeze out a bit more juice ( – , +490 -215). This was successful, but not significantly so - but hey, a free improvement's a free improvement!
Finally, my SSG shells out to git to get the update dates for each document. I consider this to be inelegant - my generator shouldn't need to run git to build properly - so I figured I'd try out an experiment and use the Rust-native gitoxide instead (, +1805 -157, closed). Unfortunately, this came with multiple costs: gitoxide does not have a convenient operation for getting the last-update-timestamp of a given file (which led to an immense amount of code bloat), and compiling gitoxide requires compiling much of a VCS (which led to an immense amount of compile-time bloat). As a result, I chose not to merge this: but I'm glad that it only took me a few hours to figure this out, and not the better part of a day!
#nixos-configuration
The majority of my systems run on NixOS. Without LLMs, I would have given up on Nix almost immediately: but they have freed me to overlook its incredibly ugly language and focus on effectively administering my systems.
During early November, I acquired a ThinkPad T480s, and had to effect a few refactors to enable the bring-up of NixOS and associated configs. My sync script was copying all of my dotfiles over to every machine, including irrelevant ones; thankfully, it was straightforward enough to break them up (–, +16 -9). I then added automatic locking to Niri (, +42 -2), and properly set up my SSH agent across machines (, +19 -7).
The last thing I did here was to extract out common developer tooling and services (, +36 -34) so that my laptop could benefit from the same tooling as my server, and vice versa.
#prismata
Prismata is a research prototype that I built out at one of my former employers, with the intention of experimenting with an AI co-creation workflow in a voxel world. After receiving permission, I open-sourced it and did some minor cleanup work to make it usable once again.
The first thing I did in this batch of work was to set up a frontend deployment workflow (–, +91 -0); unfortunately, in doing so, I discovered that the version of Bevy/wgpu in use required experimental rendering features that were no longer supported in modern browsers.
Normally, I would have given up about here, but on a lark, I decided I'd let my buddy at it: I tasked Claude with porting it to the then-latest Bevy version (, +3484 -2527, closed). And it was actually making decent headway! Unfortunately, CCW broke down and refused to accept any more prompts, which forced me to create a new PR to complete the migration ( – , +4112 -3444).
I had to go in there towards the end to restore some of the behaviour that had broken between ports, but given that I was jumping this across three versions of Bevy and through several major changes to the ECS, I'm quite happy with how everything worked out. Not sure if I'm emotionally ready to queue up the update to Bevy 0.18, though.1515Truth be told, this would not be that difficult. The most frustrating part is that I had to fork several dependencies to update them to Bevy 0.17, so I'd have to do the same thing again for 0.18. Not difficult, just annoying.
EDITOR'S NOTE: In the time it has taken for me to write this, Bevy 0.19's release is fast-approaching. Guess I'll wait for that!
#wikitext_simplified
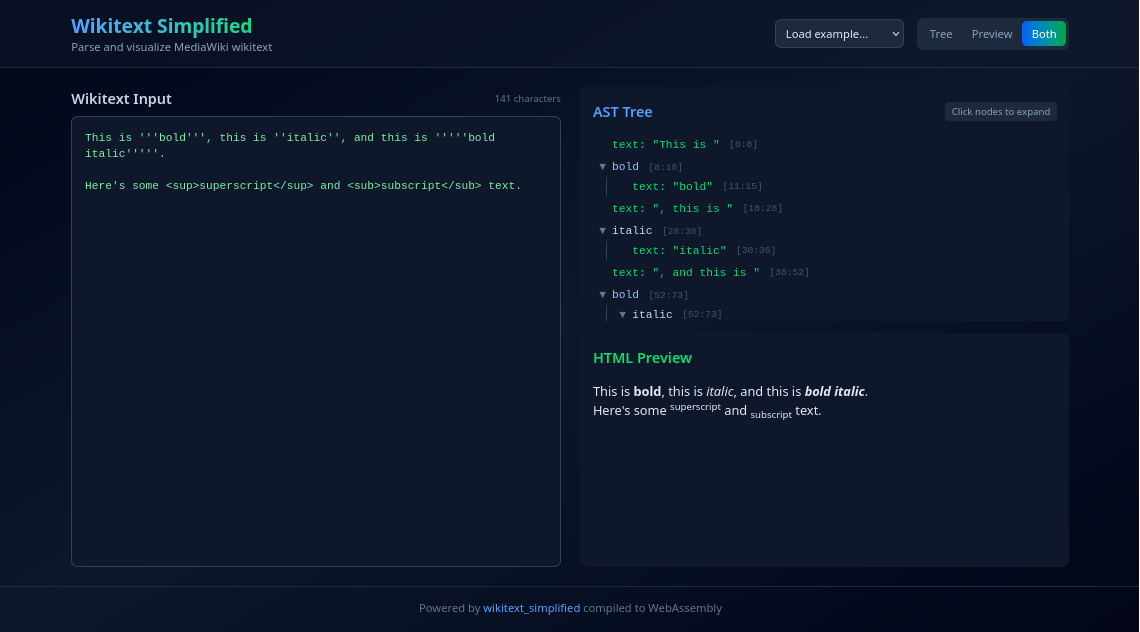
As part of my work for genresin.space, I needed a way to reliably parse wikitext within Rust. I use a fork of parse-wiki-text-2, which is itself a fork of parse_wiki_text (wherever you are, Fredrik, thank you for your service 🫡). However, PWT produces a stream of nodes: it does not actually produce a tree, at least not in the sense you'd expect from a traditional parser.
I believe that this was an intentional decision, as anyone who has worked with wikitext can tell you that it is a demonic format that will accept all kinds of malformed input and keep on trucking. For my purposes, I needed something that could take the tag soup and pull it into an AST that I could then render or process as required; from this, wikitext_simplified was born, and it has been evolved since to support more and more of the madness that permeates the wikitext of both Wikipedia and the JC2-MP wiki.
The first change that I tasked Claude with completing was to propagate the start and end positions of every node through Span and Spanned types (–, +510 -457), allowing for better downstream handling. Unlike with Pyxis, I think using externally-spanned types made sense here: there's a lot more bullshittery involved in parsing, and not everything has a meaningful span associated with it.
Some time after this, I realised it would be beneficial to demonstrate what the library actually does, so I had a React frontend (, +5710 -1) built. It is subject to the Pure Vibe Code aesthetic, much like the Perchance interpreter, but I'm okay with that: it's just a demo, after all.1616That being said, I'd be lying if I said I wasn't considering setting up a unified design language and using it across all of my tools.
#genresin.space

genresin.space is a project I've been noodling on for the last year. Using wikitext_simplified and a lot of machinery, it extracts information about every music genre with an infobox from the English Wikipedia (using the monthly dumps - I'm not hitting the live website!), and then renders it as an explorable graph (as in graph theory, not charts), so that you can explore how genres influence and are influenced by each other.
It has been functionally complete for some time, but polishing it to the point where it captures what I'm going for and works well on every platform has proven to be troublesome. Thankfully, Comrade Claude has been able to unblock some of the more pernicious work. The first change was purely procedural: splitting the build and deploy CI workflows (, +23 -44).
What I actually needed Claude for was something that had been bothering me for a long time: mobile support. I'd designed GiS with desktop in mind, but still wanted to provide a decent experience on mobile. Unfortunately, there was a particularly troubling issue that had me tearing my hair out: after a few seconds, the graph would crash Safari on iOS, and without a Mac, I had no way of debugging the problem, outside of disabling things at random. To my pleasure - and I'll admit, to some degree, annoyance - Claude was able to resolve this by tweaking a few parameters (, +223 -51).
The next steps were to improve the UI on mobile by making it properly responsive, including handling a vertical layout (–, +195 -52), and by adding snap positions for the sidebar (, +41 -10).
Finally, I'd been unhappy with the colour scheme in use for some time and wanted to support light mode, so I let Claude take a crack at that (–, +282 -110). It wasn't perfect, but it was certainly an improvement, and one that I have continued to iterate upon. (But that's for the next update.)
#openxrs
openxrs is a Rust library (not mine!) for interacting with OpenXR, the standard for interfacing with XR hardware. As part of my work on the VR mod for JC3, I wanted a D3D11 integration example for openxrs, so I used my pre-existing fork and produced such an example (, +914 -0, closed), which worked beautifully.
I then closed this PR and extracted the example into an independent repo. I would have preferred to skip directly to this step, but I wanted to make sure Claude had the necessary context to navigate openxrs without having to look up individual files.
#dwarf-c-reconstructor
After completing ida-c-splitter, I posted about it in a reverse-engineering-related Discord, and someone messaged me to ask if I could vibe-code something for them with my credits. As I was still nowhere near credit-exhaustion, I took them up on their request, and started piping their prompts and test files directly into Claude.
This essentially makes this a vibe-vibe-coded project: not only was the actual programming delegated, the task of issuing the delegation was itself delegated. I find this amusing.
In terms of methodology, my operator gave me test cases and problems they'd encountered after running the application; I would then ensure the test cases were in the repository, including everything required for complete reproduction, and then I would operate CCW with the raw problem statements. I was a little foolish in how hands-off I was being, because I found myself constantly having to explain where it could find the tests and what it was working on: spending five minutes writing a CLAUDE.md up immediately paid dividends.
With that being said, I don't think CCW was quite the right fit for this workflow. Aside from the loss of information involved in iterated-vibe-coding, its limited environment made it difficult for it to retrieve the tools required to further examine failures (e.g. utilising existing decompilers and such). Working on it locally would have also driven me to address the lack-of-context issue much sooner: my reticence to do so was borne out of a desire to touch the codebase as little as possible, but I must admit that being that hands-off was counterproductive.
I won't detail the PRs here - there were nearly forty of them, and it involved a significant amount of back and forth between all three parties involved. It exists now and it works, but I haven't personally used it, and I couldn't tell you how any of it works. How do I feel about that? Unsure; I certainly don't claim any ownership over it, despite it being under my username. Indeed, despite this being ostensibly aligned with ferrobrew's mandate, I explicitly chose not to put it there: I'm not comfortable with associating my comrade with something for which neither of us have looked at the code.
#egui-directx10
egui-directx11 is a DirectX 11 renderer for the egui immediate UI library. I had a project for Just Cause 2 that I wanted to use egui for, but unfortunately, JC2 uses DirectX 10 (one of the few games to do so!). A friend and I backported egui-directx11 to DirectX 10 some time ago, and that served us well.
However, I found myself wanting to update that project to the latest version of its dependencies, and that included egui, which meant I'd have to update egui-directx10. Nail, hammer, etc: I sent it off (–, +1662 -773). This was largely successful, but there remains a persistent bug with the text rendering that neither Claude nor I were able to figure out.
Luckily, this project is non-essential, and I'm pretty sure that we're the only people on this planet who want to use egui with DirectX 10, so I'm content with leaving it as-is.
#re-utilities
re-utilities is a library that my friend and I created to house, you'll never believe this, Utilities for Reverse Engineering. (Honestly, I can't stand the name, but we have yet to choose a better one.)
This was a comparatively mild batch of work, with only two tasks: updating windows-rs to version 0.62 (, +73 -27), and replacing anyhow with custom error enums1717anyhow is a Rust library for catch-all errors that makes it easy to handle any kind of error at the cost of removing specificity as to what the error was. The general guidance is to "use anyhow for applications, use thiserror for libraries", where thiserror is a library that offers code generation for structured errors through a procedural macro.
With the power of LLMs, it is now trivial to manually maintain these errors, and one fewer proc macro reduces compile times, even if only slightly. (, +610 -129). Nothing too difficult, but certainly not without tedium for a human.
#bevy-headless-console
As part of the JC2 work mentioned above, I also had to update bevy-headless-console (our fork of bevy-console to remove all UI integration) to Bevy 0.17. We've graduated from beating this dead horse to eviscerating it, but this was one prompt (, +65 -53).
#pyxis-defs
As part of the work done for pyxis, I introduced a monorepo of all known Pyxis definitions for use in the viewer and to make it easier to test and develop sweeping changes to Pyxis itself.
The biggest change was to switch our existing definitions over to use real generics (, +2472 -2570), as part of the companion change in Pyxis. Watching all of the redundancy disappear brought a tear to my eye.
conclusion
As mentioned at the start, these two months were some of the most productive of my life. During this period, I blew away the vast majority of my backlog - to the point where I was struggling to find work to give to Claude - and, for a time, that was liberating in itself. My grasp has always exceeded my reach by some margin, and for a brief moment, it felt like they were going to equalise.
Timeline of all 140 PRs
But I'm writing this four months on, and I'm still at it. I'm still grasping for total control over dozens of projects, and it's possible that AI is enabling my worst tendencies instead of freeing me from them. This, I'm afraid, is a subject for another blog post.1818I had a set of reflections within this post, and realised that I'd best split them out once I saw its word count steadily ascending over four thousand. Indeed, it's a subject befitting actual study, and not as a sidebar to a mere update. (Even if it is quite the update.)
What I can say, however, is that I'm very glad that I achieved what I set out to achieve, and I can only hope that my next update will come much, much sooner than this.